A Java 1.5 Parser with AST generation and visitor support. The AST records the source code structure, javadoc and comments. It is also possible to change the AST nodes or create new ones to modify the source code. Result from Ziyuan: From the result, we debug the fail test (TestIssue46) and add a breakpoint at ASTParserTokenManager: 67. And we soon realized that the bug is really around line 67 of class ASTParserTokenManager.
We feed the passed test cases from Ziyuan to Daikon. After 15 minutes, Daikon only creates a trace file larger than 1GB and does not produce any invariants. So we have to terminate it. The input of FailureDoc is a sequence. In this case, we manually create below sequence as its input. However, FailureDoc says that the sequence has not error and does not give any explanation. START SEQUENCE var0 = prim : java.lang.String:"Issue46" : var1 = method : japa.parser.ast.test.Helper.readClass(java.lang.String) : var0 var2 = method : japa.parser.ast.test.Helper.parserString(java.lang.String) : var1 var3 = method : japa.parser.ast.CompilationUnit.getComments() : var2 var4 = method : java.util.List.size() : var3 var5 = prim : int:3 : var6 = method : org.junit.Assert.assertEquals(java.lang.Object,java.lang.Object) : var5 var4 END SEQUENCE
https://code.google.com/p/javaparser/
Issue 46: https://code.google.com/p/javaparser/issues/detail?id=46&colspec=ID%20Type%20Status%20Stars%20Summary
Problem:
Using javaParser to parse a java file with more than 1 class comment, some comments are missing in the generated compilation unit.
What steps will reproduce the problem?
1. Create a Java like this:
/*
* Comment 1
*/
/*
* Comment 2
*/
/*
* Comment 3
*/
package net.perfectbug.test;
public class Test {
}
2. Parse it with JavaParser.
3. Use CompilationUnit.toString() to get the parsed source code.
What is the expected output? What do you see instead?
Expected:
All comments should be print.
Observation:
Not comments are print.
And CompilationUnit.comments only contains comment 3. It doesn't contains neither comment 1 nor comment 2.
japa.parser.ASTParserTokenManager:2275
suspiciousness: 1.00
Logic: This line is likely a bug!
Accuracy: 1.0
japa.parser.ASTParserTokenManager:72
suspiciousness: 0.67
Logic: -1.0*comment.endLine -1.0*comment.beginLine >= -7.0
Accuracy: 1.0
japa.parser.ASTParserTokenManager:67
suspiciousness: 0.67
Logic: special.specialToken.isNull
Accuracy: 1.0
japa.parser.ASTParserTokenManager:1854
suspiciousness: 0.67
Logic: -1.0*input_stream.line >= 8.0
Accuracy: 1.0
Line 2275: Only fail test cases go through this line, which makes it a likely bug. However, since we can't learn a bug explanation here, it is not fed back to users.
Line 72: We found a classifier here. But since we still not handle selective sampling for Strings with variable length, so we cannot refine this classifier using selective sampling and therefore this is not present to users.
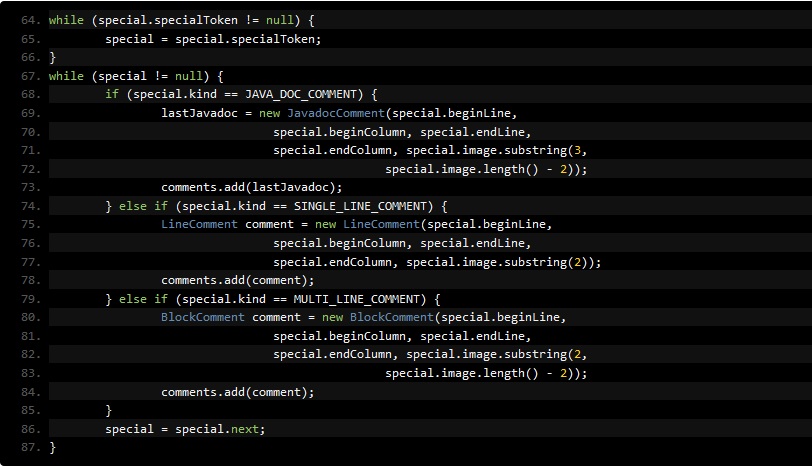
Line 67: We always try to learn using Boolean value first. For this line, we obtain a good classifier with a Boolean variable. It will be presented as the top bug explanation to users
Line 1854: Selective sampling could not improve this classifier because any change we make to input_stream.line results in exception thrown somewhere else (so that the assertion is not evaluated). We omit this classifier to users since it is not a converged result.
The output predicate:
special.specialToken.isNull == true (japa.parser.ASTParserTokenManager:67)
This is the problem: Javaparser parses a Java file into a CompilationUnit, and the variable comments in the code (as below) store comments for the whole CompilationUnit. The error happens when special.specialToken != null which means the source has more than 1 comment before a node (statement, method, class, etc.).

We remark that line 2275 is actually where special.specialToken is set to a value which makes special.specialToken != null at line 67.
The predicate above helped us understand the bug and fixed it as follows.
Fix: